
Screensiz.es è una valida risorsa per chi vuole realizzare siti dal layout responsive.
Progettare siti da fruire su dispositivi diversi non è semplice. È necessario conoscere le principali dimensioni e risoluzioni degli schermi per poter decidere le impostazioni che renderanno i nostri layout adattabili alla … Continua
- Scritto da Fabio Quarantini
- in Tutorials, Wordpress
- il 19 Dicembre 2012

Molti plugin di WordPress che utilizziamo quotidianamente aggiungono nell’output delle pagine file CSS e javascript relativi al loro funzionamento. Tutto questo non è necessariamente una cosa negativa, ma può diventare un problema quando vogliamo aggiungere personalizzazioni agli stili CSS o alle funzionalità javascript.
Per evitare di modificare direttamente i file che compongono i plugin (queste modifiche vengono eliminate durante l’aggiornamento) o riempire il nostro foglio di stile utilizzando la direttiva !important, WordPress mette a disposizione delle funzioni apposite. Grazie ad esse potremo: … Continua
- Scritto da Michela Giovanzana
- in Daily Code
- il 27 Settembre 2012

Caniuse.com è un’utilissima risorsa per web designer e developer in cui è possibile consultare tutte le funzionalità HTML5, CSS3 e SVG supportate dai browser.
Questo comodo servizio web è stato creato da Alexis Deveria per realizzare siti compatibili con i browser più utilizzati e con i dispositivi mobile.
Non tutte le funzionalità, infatti, sono supportate da tutti i browser ed è meglio verificare in anticipo se ci possono essere problemi di compatibilità.
Se la maggior parte dei visitatori non visualizza il sito correttamente, Caniuse.com permette di … Continua

FlexSlider è uno tra i migliori slider di immagini per jQuery che presenta infinite possibilità di personalizzazione. Uno dei suoi punti di forza è quello di poter realizzare in pochi passaggi uno slider responsive compatibile con la gesture swipe dei dispositivi touch.
L’utilizzo è molto semplice e, come spiegato nella documentazione ufficiale, prevede l’inserimento di contenuto html oltre alle immagini. Questo ci permette di creare slider per utilizzi specifici, il tutto attraverso un markup pulito e semantico.
Il plugin è stato acquistato recentemente da Woothemes e aggiornato alla versione 2 che introduce nuove proprietà come la possibilità di creare carousel. Il funzionamento è testato sulla maggior parte dei browser moderni come Safari 4+, Chrome 4+, Firefox 3.6+, Opera 10+, IE7+ e su dispositivi mobili iOS e Android. Per funzion … Continua

L’evento su social media e marketing più importante della zona è giunto quest’anno alla sua terza edizione. Il 20 Giugno, presso il Castello di Malvezzi a Brescia, si è svolto il Pane, Web e Salame 3.
Il social media camp nostrano ha seguito il format ormai consolidato degli speech di 20 minuti, presentati sul palco del PWeS3 da una ventina di relatori. … Continua

Venerdì 4 e Sabato 5 Maggio, nello spazio del Museo Sagsa, Ripa di Porta ticinese 111, si è tenuta la 5° edizione del WordCamp Milano 2012.
WordCamp – Day 1
Seduti attorno al tavolo del WordCamp, si sono riunite alcune personalità note al mondo di WordPress. Niente speech per loro, ma una semplice e informale chiacchierata per analizzare l’evoluzione che ha avuto la piattaforma, sempre più utilizzata per funzioni che vanno oltre al semplice blogging. Scelgono di affrontare la giornata in maniera interattiva facendo relazionare e partecipare anche il pubblico. La sala è piena e anche da casa gli interventi vengono seguiti grazie alla diretta streaming, a tratti disturbata. Anche su Twitter si cinguetta parecchio, tant’è che l’hastag #iwordcamp entra dopo un’ora nei TT Italia in terza posizione, superando Giulio Andreotti. … Continua

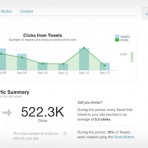

 Robots.txt e Google Webmaster Tools
Robots.txt e Google Webmaster Tools Come sostituire il logo di WordPress nei pannelli login e admin
Come sostituire il logo di WordPress nei pannelli login e admin Come fare il backup di Wordpress
Come fare il backup di Wordpress Screensiz.es – Tutte le risoluzioni per realizzare siti responsive
Screensiz.es – Tutte le risoluzioni per realizzare siti responsive Come disabilitare css e javascript dei plugin WordPress
Come disabilitare css e javascript dei plugin WordPress Caniuse.com – Risorsa per web designer e developer sulle funzionalità CSS3, HTML5 e SVG supportate dai browser
Caniuse.com – Risorsa per web designer e developer sulle funzionalità CSS3, HTML5 e SVG supportate dai browser