Robots.txt e Google Webmaster Tools
- Scritto da Giulia Ballarin
- in HTML e CSS, Tutorials
- il 24 Gennaio 2012
- Commenti

Come funziona un crawler
Un crawler – altrimenti detto robot, spider o bot – è un software che, in modo sistematico, cerca e analizza contenuti testuali all’interno una rete per conto di un motore di ricerca allo scopo di inserirli in un indice consultabile. Normalmente questi software cercano di scovare il maggior numero possibile di dati da catalogare ed è quindi opportuno indirizzare le loro scansioni.
Come sappiamo infatti, molto spesso all’interno di un sito sono presenti pagine che non si vuole appaiano nei risultati dei motori di ricerca. Il file robots.txt ci aiuta nel compito di regolamentare le visite dei crawler.
La prima cosa che fa uno spider quando visita un indirizzo è cercare il file robots.txt nella directory principale. Una volta trovato, ne legge il contenuto e ne segue le indicazioni, sem … Continua
Holmes.css un detective per il vostro markup
- Scritto da Giulia Ballarin
- in HTML e CSS, Tutorials
- il 26 Ottobre 2011
- Commenti

Holmes è un file CSS che, grazie all’utilizzo di pseudo-classi, pseudo-elementi e selettori d’attributo, è in grado di evidenziare markup HTML non valido, inaccessibile o errato.
Errori, avvisi e proprietà CSS deprecate
Utilizzando holmes.css possiamo individuare, attraverso bordi di colori differenti, errori, avvertimenti ed elementi CSS deprecati per le seguenti categorie:
- attributi mancanti, come l’attributo name per i tag di input
- markup migliorabile, come i link con href=”#”
- elementi deprecati e non conformi al W3C
- attributi non W3C
Come analizzare il nostro codice
Utilizzare holmes.css è molto semplice: una volta scaricato il file, basterà richiamar … Continua
Twitter Web Analytics – La Social Analytics di Twitter
- Scritto da Giulia Ballarin
- in Social Network, What's New
- il 20 Settembre 2011
- Commenti
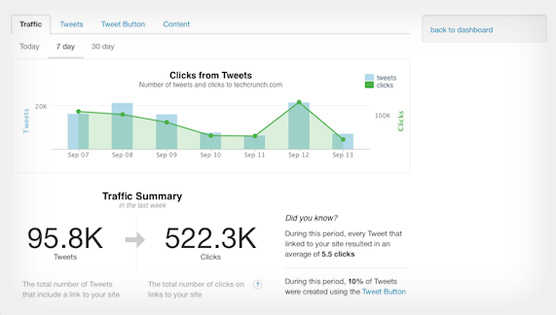
Come annunciato in luglio, la piattaforma di social analytics BackType è stata acquisita da Twitter. Il risultato di questa fusione, a due mesi di distanza, è il rilascio di un sistema per il monitoraggio e l’analisi del traffico proveniente dal social. Il servizio è stato battezzato, con il più classico dei nomi e in perfetto stile Google, Twitter Web Analytics.
Twitter Web Analytics si occuperebbe principalmente di … Continua
Humans.txt – Oltre il tag author
- Scritto da Giulia Ballarin
- in Utility, Web Tips
- il 13 Settembre 2011
- Commenti

Cos’è humans.txt
Humans.txt è un semplice file di testo che raccoglie informazioni su quanti hanno contributo alla realizzazione di un sito web. L’iniziativa consiste nel segnalare nomi, ruoli e contatti di tutti le persone che vi hanno lavorato: dagli sviluppatori ai grafici, dai copywriter ai SEO, ognuno avrà i suoi credits.
Il nome humans è una sorta di gioco di parole in opposizione a robots, termine con cui viene indicato il file letto unicamente dai crawler.
Il file humans
Il file deve essere inserito nella root del sito, proprio come il robots.txt, e può essere richiamato da un tag autore collocato nella sezione <head> come se … Continua
Pane, web e salame: il social media camp
- Scritto da Giulia Ballarin
- in Eventi, What's New
- il 25 Giugno 2011
- Commenti

Il 23 giugno 2011 #pwes è stato uno degli hashtag più utilizzati su Twitter. Questo perché eravamo veramente in molti a seguire i convegni organizzati per questa seconda edizione del Pane, Web e Salame.
Come affermato durante l’apertura della giornata, e come ribadito sulla home del sito, PWeS2 è
una conferenza aperta dove si discute di Social Media, web 2.0 & imprese, best practice locali e nazionali. Tutto in un ambiente informale ma professionale.
E così è stato. Si sono alternati al microfono professionisti del settore, politici, docenti universitari, imprenditori e commercianti i cui interventi hanno evidenziato, in modo unanime, l’importanza e l’evoluzione dei social media sia in rete che … Continua
Utilizzare i canali personalizzati di Google AdSense per migliorare i rapporti sul rendimento
- Scritto da Giulia Ballarin
- in Google Tools, Tutorials
- il 5 Febbraio 2011
- Commenti
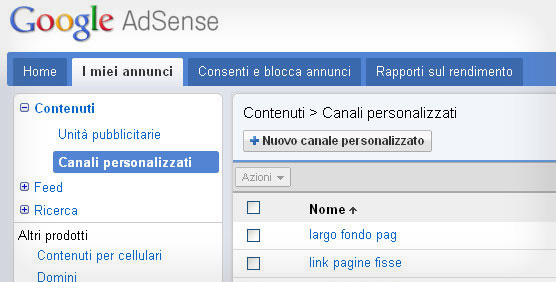
Prima dell’introduzione della nuova interfaccia AdSense i publisher potevano visualizzare di default solo i guadagni in dati aggregati – ossia nel loro complesso – e suddivisi unicamente per periodo o tipologia.
Ciò che interessa ai publisher, però, è conoscere il rendimento del singolo annuncio o sito. Considerando la possibilità di ogni persona di possedere un solo account AdSense si può comprendere quanto sia importante riuscire a dist … Continua
Articoli popolari
-
 Robots.txt e Google Webmaster Tools
Robots.txt e Google Webmaster Tools -
 Come sostituire il logo di WordPress nei pannelli login e admin
Come sostituire il logo di WordPress nei pannelli login e admin -
 Come fare il backup di Wordpress
Come fare il backup di Wordpress
 Screensiz.es – Tutte le risoluzioni per realizzare siti responsive
Screensiz.es – Tutte le risoluzioni per realizzare siti responsive Come disabilitare css e javascript dei plugin WordPress
Come disabilitare css e javascript dei plugin WordPress Caniuse.com – Risorsa per web designer e developer sulle funzionalità CSS3, HTML5 e SVG supportate dai browser
Caniuse.com – Risorsa per web designer e developer sulle funzionalità CSS3, HTML5 e SVG supportate dai browser